
Personal Information: Definitions and Examples
Every day, extensive amounts of personal data are collected, stored, and processed by web applications, social networks, advertising networks, employers, healthcare providers and more. But what exactly counts as personal information, and why does it matter?
Personal information, or personal data, refers to any information that relates to an identifiable natural person. This concept now goes well beyond conventional identifiers like your name or home address, including digital traces that, just ten years ago, were hardly regarded as personal information.
This guide breaks down the essential personal information examples you need to know, explores how they’re protected under frameworks like the General Data Protection Regulation, and provides best practices for safeguarding this sensitive data.
Key Takeaways
• Personal information encompasses a wide range of data that can identify or be linked to an identifiable living individual, including traditional identifiers such as names and addresses, as well as digital markers like IP addresses and online identifiers.
• Sensitive personal data, such as health information, racial or ethnic origin, political opinions, and biometric data, requires heightened protection and explicit consent under data protection regulations like the General Data Protection Regulation (GDPR).
• Organisations must implement strong data protection measures, including lawful data processing, data minimisation, encryption, access controls, and regular audits, to ensure compliance with privacy laws and maintain trust with individuals.
Introduction to Personal Information
The concept of personal information is central to data protection and privacy laws worldwide. These frameworks aim to safeguard individuals’ rights and freedoms by regulating how organisations collect, use, and protect data relating to identifiable natural persons.
Personal data is stored by numerous entities, including:
• Web applications
• Social media platforms
• Advertising networks
• Employers
• Healthcare providers
• Public authorities
• Financial institutions
This widespread collection has a significant impact on individuals’ ability to control their data privacy and necessitates the implementation of proper data protection measures. Understanding what constitutes personal information is crucial for organisations to ensure compliance with regulations and maintain trust with their customers.
Definition and Examples
Personal data means any information relating to an identified or identifiable natural person (data subject), who can be directly or indirectly identified by reference to an identifier such as a name, an identification number, location data, an online identifier or to one or more factors specific to the physical, physiological, genetic, mental, economic, cultural or social identity of that natural person.
This broad definition ensures that privacy laws can adapt to evolving technology and emerging data types. Let’s explore various kinds of personal information examples:
Basic Identifying Information
• Full name
• Physical address
• Mailing address
• Phone number
• Email address
• Date of birth
While some of these items alone (such as a common last name) might not identify a person, their combination typically can identify an individual directly.
Official Identification Numbers
• Passport numbers
• Driver’s license numbers
• Social Security numbers
• Customer or account numbers
• Tax identification numbers
These identifiers are often subject to heightened legal protection due to their sensitive nature and potential for misuse.
Online Identifiers
• IP addresses (both IPv4 and IPv6)
• Device IDs
• Cookies
• Advertising identifiers
• Username/login credentials
• Internet browsing history
When you browse websites, your IP address is considered personal data under modern privacy frameworks. These digital markers, once thought to be anonymous, are now recognised as personal information because they can be used to single out individuals.
Commercial and Financial Information
• Credit card details
• Bank account numbers
• Purchase histories
• Transaction records
• Billing information
Such records not only have financial implications but can reveal significant insights about a person’s behaviour and preferences.
Biometric Information
• Fingerprints
• Facial recognition templates
• Voiceprints
• Retina scans
• DNA profiles
These physical characteristics are increasingly used for authentication and are considered personal data requiring special protection.
Behavioral Data
• Search queries
• Website interactions
• App usage patterns
• Location data
• Travel patterns
These data points reveal habits, routines, and preferences that can be used to create detailed profiles of individuals.
Personal Characteristics
• Age
• Gender
• Race
• Religion
• Sexual orientation
• Political opinions
• Trade union membership
Many of these characteristics fall under special categories of personal data that require additional protections.

Sensitive Information
Sensitive personal data, also known as special category data in some frameworks, represents a critical subset of personal information that requires heightened protection due to its potential to cause significant harm if misused.
Examples of sensitive personal data include:
• Health data and medical records
• Racial or ethnic origin
• Political opinions
• Religious or philosophical beliefs
• Trade union membership
• Genetic data
• Biometric data used for identification
• Information about sex life or sexual orientation
• Criminal conviction data (in many jurisdictions)
The potential for discrimination, stigmatisation, or other harms makes sensitive data especially risky. For example, unauthorised disclosure of health information could lead to employment discrimination or social stigma.
Storage Requirements
Sensitive personal data must be stored separately from other personal data, with physical storage being secure, such as locked drawers or filing cabinets, and digital files being encrypted or pseudonymised. Organisations processing sensitive information must implement additional safeguards:
• Physical security measures (restricted access areas, secure cabinets)
• Advanced encryption for digital storage
• Strict access controls based on need-to-know principles
• Regular security audits and vulnerability assessments
Consent Requirements
Under the General Data Protection Regulation (GDPR) and similar frameworks, explicit consent is typically required to process sensitive personal data. Failure to understand the nuances of consent can lead to fines, enforcement actions, and reputational damage.
Explicit consent means the data subject must clearly and affirmatively agree to the processing through a statement or other explicit affirmative action; implied consent is insufficient for sensitive data.
Data Processing and Protection
Data protection laws limit the amount of personal information businesses can collect, and organisations must take adequate precautions to secure and keep personal data private throughout its lifecycle.
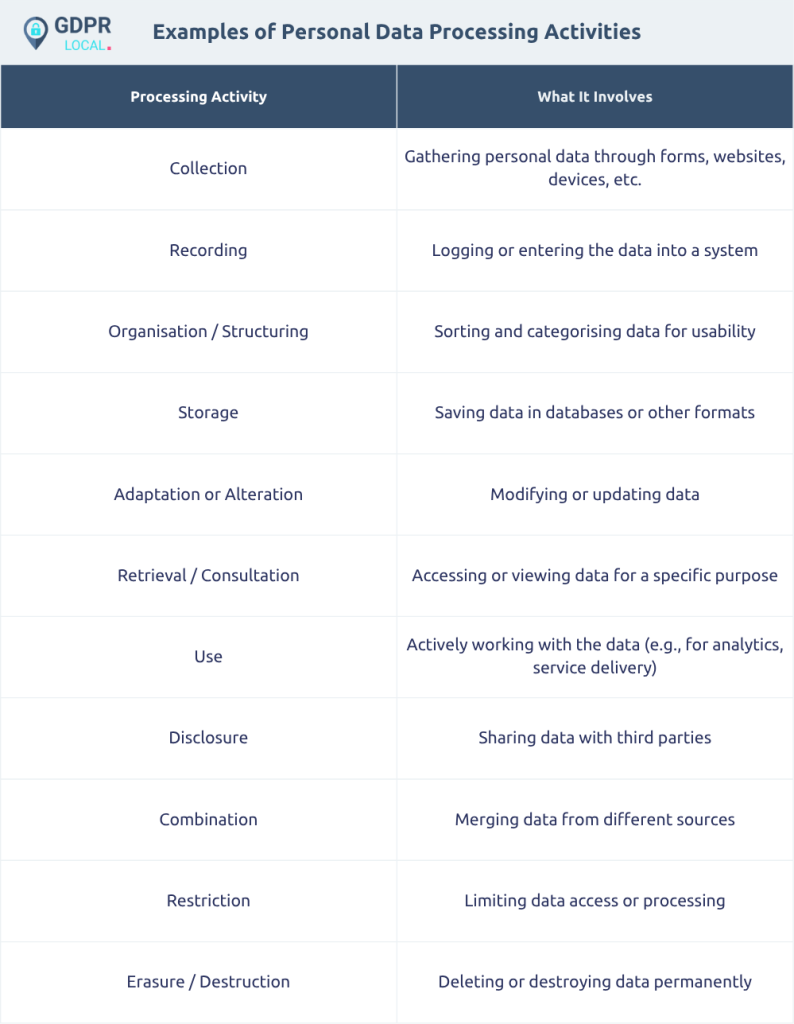
Processing personal data encompasses any operation performed on personal information, including:
• Collection
• Recording
• Organisation
• Structuring
• Storage
• Adaptation or alteration
• Retrieval
• Consultation
• Use
• Disclosure
• Combination
• Restriction
• Erasure
• Destruction
Personal data processing must be conducted in a manner that ensures the confidentiality, integrity, and availability of the information, utilising appropriate technical and organisational measures.
Key Data Protection Principles
Organisations protecting personal information should follow recognised data privacy principles, such as the Fair Information Practices, which provide guidelines for data protection:
1. Lawfulness, fairness, and transparency: Processing must have a legal basis and be conducted in a fair, transparent, and lawful manner.
2. Purpose limitation: Personal data should only be collected for specific, explicit, and legitimate purposes.
3. Data minimisation: Only data necessary for the stated purpose should be collected.
4. Accuracy: Personal information must be kept accurate and up-to-date.
5. Storage limitation: Data should not be kept longer than necessary for the stated purpose.
6. Integrity and confidentiality: Appropriate security measures must protect against unauthorised processing, accidental loss, or destruction.
Implementing these principles requires both technical safeguards (such as encryption and access controls) and organisational measures (policies, staff training, and access restrictions).
Anonymisation and Pseudonymisation
Anonymisation and pseudonymisation represent two distinct approaches to reducing privacy risks when handling personal data, each with different regulatory implications.
Anonymisation
Anonymised data no longer relates to an identified or identifiable natural person and falls outside the scope of data protection regulations such as the GDPR. For data to be truly anonymised:
• The process must be irreversible
• No individual can be singled out from the data
• The data cannot be linked to other information to identify an individual
• No one, including the data controller, can re-identify the data subject
When data is properly anonymised, it’s no longer considered personal data because the individual is no longer identifiable. This makes anonymisation an attractive option for research, statistics, and other data-intensive activities.
Pseudonymisation
Pseudonymisation replaces or removes identifiers, so that data cannot be attributed to a data subject without additional information, which must be kept separately and protected through technical and organisational measures to prevent identification.
Unlike anonymisation, pseudonymised data remains personal data under data protection regulations and is still subject to data protection rules. The additional information needed to identify individuals is held separately and subject to security measures.
Examples of pseudonymisation techniques include:
• Replacing names with random identifiers
• Data masking
• Encryption with separate key storage
• Tokenisation
Pseudonymisation reduces risks to data subjects and supports compliance while maintaining data utility. It’s beneficial in circumstances where complete anonymisation would render the data useless for its intended purpose.
Anonymising data is encouraged to limit risk, but it’s essential to recognise that processing occurs at the point of anonymisation, requiring careful consideration and implementation.
Regulations and Compliance
The General Data Protection Regulation and similar frameworks worldwide have revolutionised how organisations must approach personal information management.
Data protection regulations impose obligations on organisations to protect personal data and respect individuals’ rights. These frameworks are increasingly stringent, with substantial penalties for non-compliance.
Key Regulatory Requirements
Organisations must ensure compliance with regulations by:
1. Implementing comprehensive data protection policies and procedures that govern the collection, use, and disposal of personal information.
2. Conducting Data Protection Impact Assessments (DPIAs) for high-risk processing activities to identify and mitigate potential privacy risks.
3. Designating a Data Protection Officer (DPO) in certain circumstances to oversee compliance efforts and serve as a point of contact for data subjects and supervisory authorities.
4. Maintaining records of processing activities to demonstrate compliance with regulatory requirements.
5. Providing individuals with rights regarding their data, including:
• Right of access
• Right to rectification
• Right to erasure (“right to be forgotten”)
• Right to restrict processing
• Right to data portability
• Right to object to processing
Consequences of Non-Compliance
Non-compliance with regulations can result in severe consequences:
• Enforcement actions by regulatory authorities
• Reputational damage affecting customer trust
• Civil litigation from affected data subjects
• Business disruption during investigations
Organisations must stay up-to-date with regulatory developments and changes to ensure ongoing compliance and maintain trust with their customers. This often requires dedicating resources to privacy governance and regularly reviewing data protection practices.
Best Practices
Implementing strong best practices for personal data protection not only ensures regulatory compliance but also builds essential trust with customers and stakeholders.
Organisational Measures
Organisations should implement best practices for data protection, including:
1. Regular data protection audits should be conducted to identify and address potential vulnerabilities in the handling of personal information.
2. Comprehensive employee training programs that ensure all staff understand their responsibilities regarding personal data.
3. Incident response plans that enable rapid containment and notification in the event of a data breach.
4. Data classification systems that correctly identify different categories of personal information and apply appropriate protection levels.
5. Privacy governance structures with clear roles and responsibilities for data protection.
Technical Safeguards
Data protection by design and by default should be integrated into organisational processes, ensuring that personal data is protected from the outset:
1. Access controls limit data access to authorised personnel on a need-to-know basis.
2. Encryption for sensitive data both at rest and in transit.
3. Secure deletion procedures ensure that data is completely removed when no longer needed.
4. Network security measures include firewalls, intrusion detection, and secure configurations.
5. Regular security updates and patches to address known vulnerabilities.
Ongoing Monitoring and Improvement
Continuous monitoring and evaluation of data protection practices are essential to ensure ongoing compliance and maintain trust with customers:
1. Regular policy reviews are crucial for staying current with evolving regulations and technologies.
2. Privacy impact assessments for new projects or systems that process personal information.
3. Vendor management processes ensure that third parties handle personal data responsibly and in accordance with applicable laws and regulations.
4. Documentation of compliance efforts to demonstrate due diligence to regulators, if needed.
Organisations should prioritise transparency and accountability, providing clear information to individuals about how their data is processed and protected. This includes clear privacy notices, accessible data subject request procedures, and honest communication about data practices.
Conclusion
The definition of personal information continues to evolve as our lives become increasingly digital and data-driven. Today, organisations collect more data about individuals than ever before, and with that comes a greater responsibility. Protecting this information means staying compliant, but it also indicates that the organisation is working fully towards the interest of the customer, which ultimately earns their trust.
Companies must stay up-to-date on what constitutes personal data and how to protect it effectively. Stronger protections, respecting the rights of users and integrating privacy into systems from the beginning, are now a must.
Take time to review your organisation’s data inventory to identify all personal information examples being processed, and ensure appropriate safeguards are in place for each category, particularly for sensitive personal data that requires enhanced protection.
Frequently Asked Questions (FAQs)
What is the difference between personal information and sensitive personal data?
Personal information refers to any data that can identify or be linked to an identifiable natural person, such as names, addresses, or IP addresses. Sensitive personal data, also known as special category data, includes information that requires higher protection due to its nature, such as health data, racial or ethnic origin, political opinions, and biometric data.
Can anonymised data still be considered personal information?
No, anonymised data is information that has been processed in such a way that individuals can no longer be identified, either directly or indirectly. Properly anonymised data falls outside the scope of data protection regulations because it does not relate to an identifiable living individual.
What measures should organisations take to protect personal information?
Organisations should implement technical and organisational safeguards such as data minimisation, encryption, access controls, regular audits, and staff training. They should also ensure compliance with relevant regulations, such as the General Data Protection Regulation (GDPR), and obtain explicit consent when processing sensitive personal data.